解析字幕
根据音、视频资源和与其相匹配的字幕数据来训练外语听说能力是一字幕浏览器扩展的核心。
而获取音、视频中的字幕数据就成为了核心中的核心。
一字幕浏览器扩展目前可以适配 youtube.com (opens in a new tab)、bilibili.com (opens in a new tab) 视频站点。后续还会陆续适配其它视频站点,敬请期待。
还好,现在已经步入 AI 时代。并且现在已经有很多利用 AI 技术解析音、视频文件(如:.mp3, .mp4 等等文件)中文本(字幕)的开源技术框架。
下面字幕君就带给大家其中一种开源,免费,快速,高效的解析方法。
whisperX
选择 whisperX https://github.com/m-bain/whisperX (opens in a new tab) 是因为它很好地解决了 OpenAI 的 whisper https://github.com/openai/whisper (opens in a new tab) 解析播放时长大的文件时,字幕时间精度不准和解析速度慢的两大问题。
当然,如果你还有更好的方法,也可以使用您自己的方法。我也一直在寻找更快,更好的方法。
电脑操作能力、解决问题能力强的同学可以继续往下看。操作水平欠佳的同学请就此打住,可以去网上找找其它的替代方案。
系统要求
- 最好使用
Windows+Nvidia显卡的机器。众所周知的原因,英伟达显卡在AI计算上有非常大的优势。没有 Nvidia 显卡,或是使用 Mac 的同学也可以用,但是速度会慢很多。 - 有
Nvidia显示的Windows机器,需要安装CUDA和cuDNN,以加快解析速度。关于CUDA和cuDNN的安装可以查看本站提供的简要说明 安装CUDA和cuDNN,也可以自行咨询AI和 搜索引擎。
安装
- 创建
whisperX的conda虚拟环境,不知道conda的同学可以自行搜索了解。conda其实是个好东西。conda的教程请点击>>>https://conda.io/projects/conda/en/latest/user-guide/getting-started.html (opens in a new tab)(可能需要魔法上网才能打开)。或是查看本站简要说明 关于Conda
conda create --name whisperx python=3.10
conda activate whisperx-
Install PyTorch, e.g. for Linux and Windows CUDA11.8:
官方用的是
CUDA11.8,而我本机上已经安装了CUDA11.7,所以,我就没有动。直接把它的命令改了。
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
修改为如下命令
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
就改了 CUDA 的版本号 11.8 => 11.7
- 安装
repo
pip install git+https://github.com/m-bain/whisperx.git
- 查看帮助信息
whisperx -h
- 开始解析
whisperx 功夫熊猫2.mp3whisperx 功夫熊猫2.mp4解析 mp3,mp4 都是可以的。
或者是如下命令:
whisperx --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --language en 功夫熊猫2.mp4可能出现的问题
需要 VPN
安装过程可能会需要魔法(VPN)上网,以下载所需要的必备文件。

cublas64_12.dll 找不到
出现如下问题: RuntimeError: Library cublas64_12.dll is not found or cannot be loaded

解决办法:

按上述方法,修改了 bin 目录下的文件名就可以了。我是升高了版本,cublas64_11.dll 修改为 cublas64_12.dll
下载 models 出错
whisperx --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --language en F:\功夫熊猫2.mp3在运行如上命令时,出现问题:
下载文件时总是出错。网络问题。下载到一半 40% 多时退出,出错。
raise ProtocolError(arg, e) from e
urllib3.exceptions.ProtocolError: ('Connection broken: IncompleteRead(1310237429 bytes read, 1776675533 more expected)', IncompleteRead(1310237429 bytes read, 1776675533 more expected))

提示缺少文件,需要找到 Systran--faster-whisper-large-v2。
解决办法:
在 huggingface.co 关于huggingface 中可以找到 Systran--faster-whisper-large-v2,链接为: https://huggingface.co/models?sort=trending&search=Systran--faster-whisper-large-v2 (opens in a new tab)

链接分别为:
-
https://huggingface.co/Systran/faster-whisper-large-v2/tree/main (opens in a new tab)
-
https://huggingface.co/Systran/faster-whisper-large-v2/blob/main/model.bin (opens in a new tab)

下载完成后,把这个文件 model.bin 放在如下文件夹下就可以了。
这个文件
model.bin使用浏览器下载,中间可能会断好几次。 最终还是成功了。
C:\Users\Administrator\.cache\huggingface\hub\models--Systran--faster-whisper-large-v2\snapshots\f0fe81560cb8b68660e564f55dd99207059c092e
首次运行后,它会下载如下文件:wav2vec2_fairseq_large_lv60k_asr_ls960.pth,如图:

最后生成的字幕文件在命令运行的目录下面,如:f:\ ,而不是在视频所在的目录下,这一点需要注意!
SHA256 不匹配
可能出现如下问题
RuntimeError: Model has been downloaded but the SHA256 checksum does not not match. Please retry loading the model.解决办法 (参考链接:https://github.com/m-bain/whisperX/issues/449 (opens in a new tab)) :

删除如下路径 C:\Users\Administrator\.cache\torch 中的文件:

再次运行即可

huggingface.co
huggingface.co 的介绍,由 AI 生成,仅供参考。Hugging Face (opens in a new tab) 是一个专注于自然语言处理(NLP)的开源平台。它主要提供以下几个方面的服务和资源:
-
预训练模型库:Hugging Face 提供了大量的预训练语言模型,这些模型可以用于各种NLP任务,如文本分类、情感分析、机器翻译、问答系统等。
-
模型训练和微调:用户可以使用Hugging Face提供的工具和框架来训练和微调自己的语言模型。
-
模型托管:Hugging Face 提供模型托管服务,用户可以将自己的模型托管在平台上,方便进行模型的部署和使用。
-
社区支持:Hugging Face 拥有一个活跃的社区,用户可以在社区中分享经验、讨论问题、获取帮助。
-
文档和教程:Hugging Face 提供详细的文档和教程,帮助用户了解如何使用平台和模型。
-
API服务:Hugging Face 提供API服务,允许用户通过API调用模型进行NLP任务处理。
-
模型市场:Hugging Face 有一个模型市场,用户可以在这里发现和下载其他用户共享的模型。
-
教育和研究:Hugging Face 也支持教育和研究活动,提供资源和工具帮助研究人员和学生进行NLP相关的研究。
总之,Hugging Face 是一个综合性的NLP资源平台,旨在促进自然语言处理技术的发展和应用。
https://huggingface.co/models (opens in a new tab) 你想要的 models 都在里面。

关于解析时间
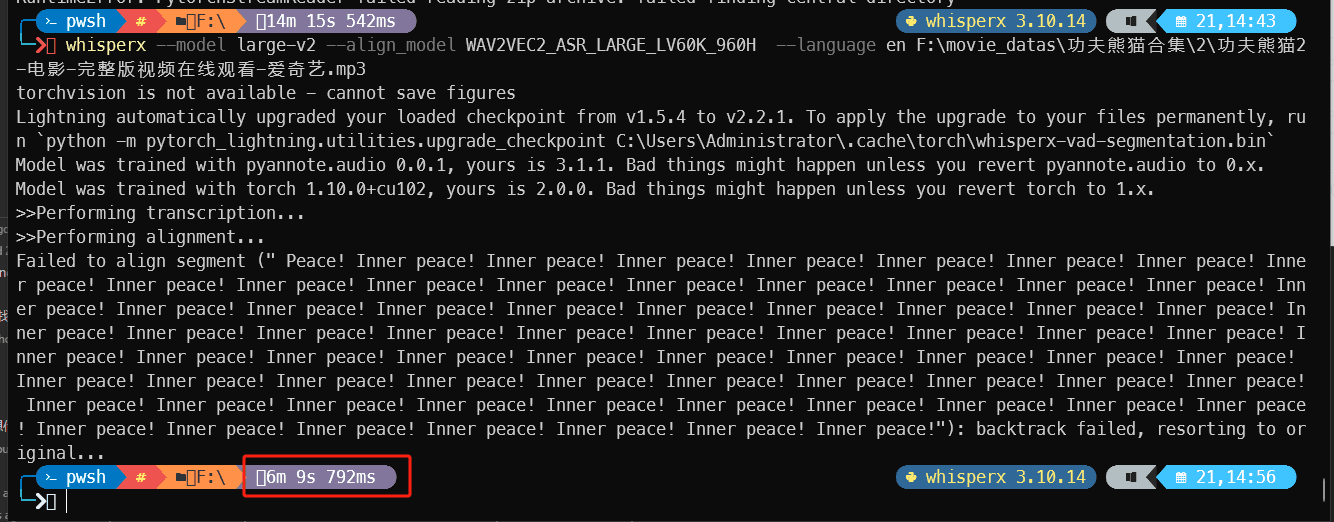
使用默认参数命令 解析 一整部 功夫熊猫2 的音频,只要 3分16秒。
whisperx F:\功夫熊猫2.mp3
使用 参数 large-v2 模型 命令,解析需要的时间是 6分9秒,也非常快了!
whisperx --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --language en F:\功夫熊猫2.mp3